Machine Learning Verification Example and Adversarial Attacks
We will review the high-level concept of verification for machine learning models. This brief will cover input-output specifications, adversarial examples, and adversarial attacks.
For the purpose of this brief, we consider a ML model simply a mapping from inputs to outputs.
Example:
Recall again our classification example in ML Intro brief. In that example, we try to predict whether a given coordinate is in one of Singapore islands or not. The input space is the set of all possible coordinates (lon, lat) and the output space is the set of binary labels {0, 1}, where 0 means the coordinate is not in Singapore and 1 means the coordinate is in Singapore islands.
 Fig. 1: The classification example in ML Intro brief.
Fig. 1: The classification example in ML Intro brief.
Input-Output Specifications
Input-output specifications is a way to formalize the expected behavior of the model. It constraints the model to produce certain outputs for certain inputs (hence the name). To illustrate this, consider the following example.Suppose now we have a point (lon, lat) that we know is in Singapore islands and sufficiently far from the sea (e.g., some distance \(\epsilon\) away). We can then use the point as a center for some neighborhood around it and expect the model to output 1 for any point within the neighborhood.
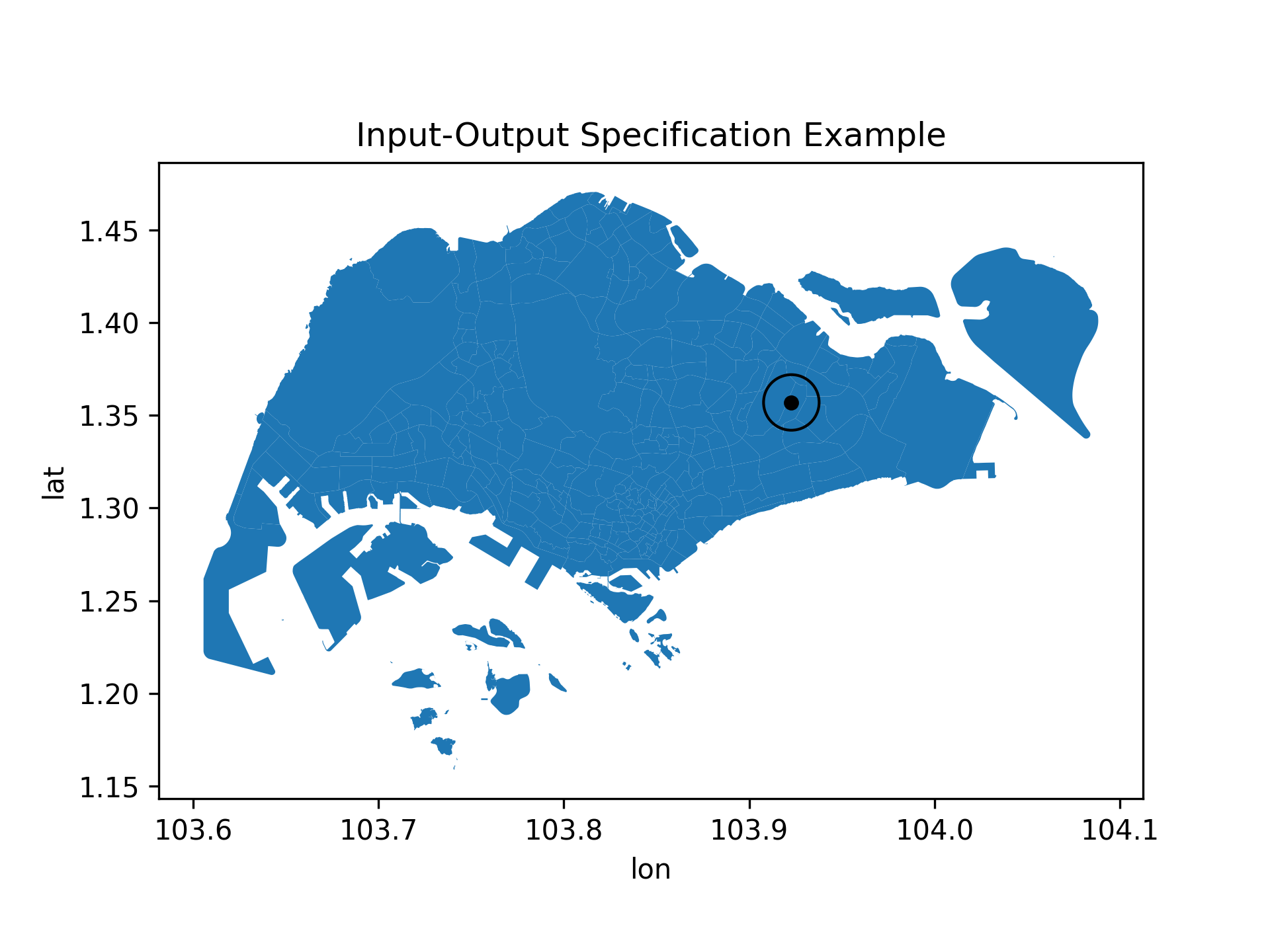 Fig. 2: Input-output specification example. If we know the black point is in Singapore islands and is \(\epsilon\)-far from the sea, we can expect the model to output
Fig. 2: Input-output specification example. If we know the black point is in Singapore islands and is \(\epsilon\)-far from the sea, we can expect the model to output 1 for any point within the radius of \(\epsilon\).
If, however, the model outputs 0 for some points within the neighborhood, then the model violates this input-output specification.
We can of course have more complex input-output specifications. For example, we can have multiple points with different labels and expect the model to output the same label for points within some neighborhood of each point.
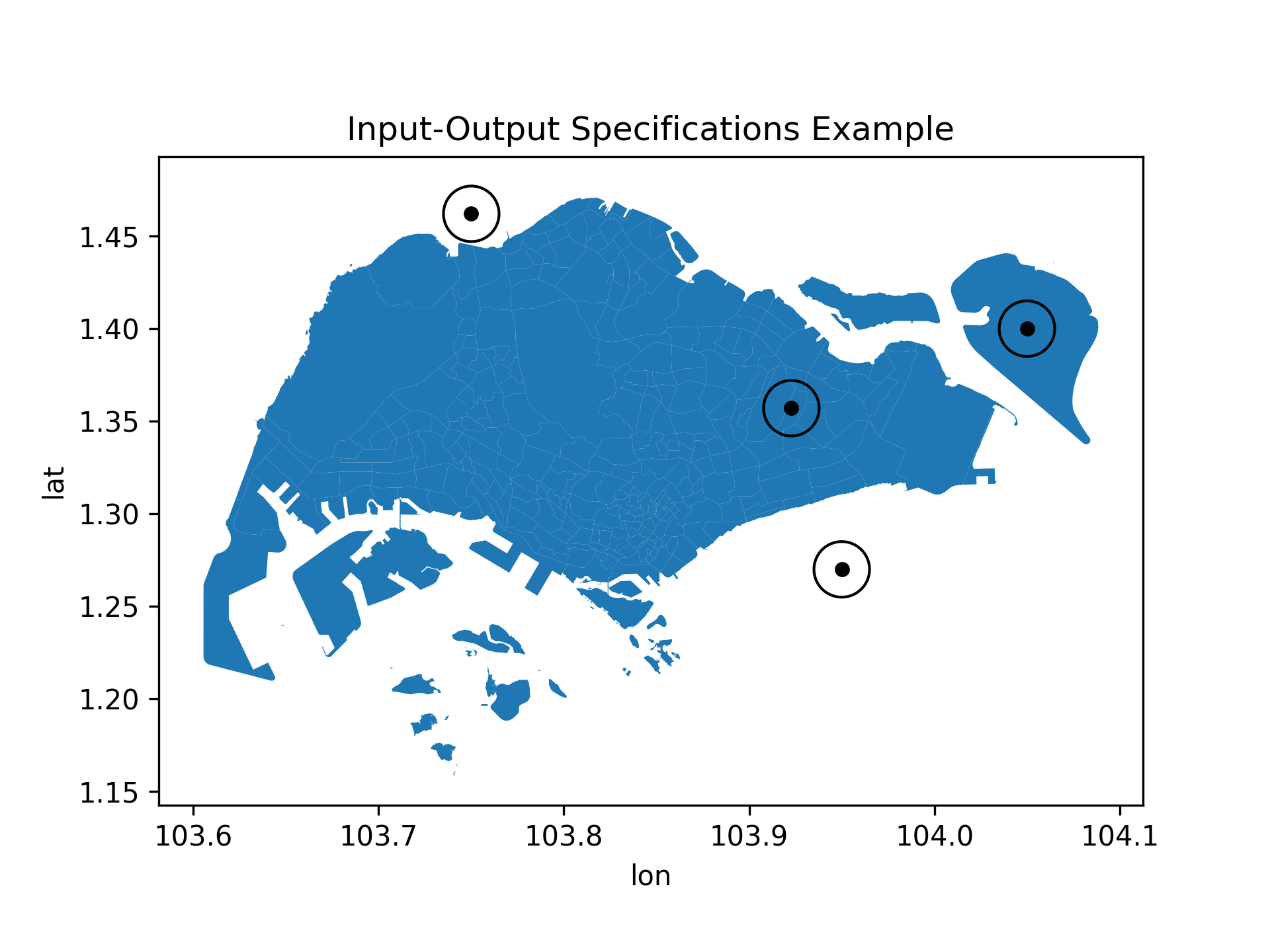 Fig. 3: Input-output specification example with multiple points. We can expect the model to output the same label for points within some neighborhood of each point.
Fig. 3: Input-output specification example with multiple points. We can expect the model to output the same label for points within some neighborhood of each point.
Given such input-output specifications, we can then verify if model satisfies the given specifications. If the model violates the specification, then we can include that in our verification report. This violation can be due to several reasons, such as:
- the model is not trained properly,
- the model is not robust to noise, or
- the model is not general enough.
With such information, we can then improve the model by retraining it with more data, adding regularization, or using more complex models. This is the essence of verification for ML models.
For our example, the model fails the input-output specifications (see, for example, the top circle where most of the points are labeled 1 by the model, while in fact, they should be labeled 0). This is because the model is not trained properly to cover the top part of the map. In fact, looking at the dataset, we can see that the model is trained on a dataset that does not cover the top part of the map. This is a common problem in ML models, where the model is not general enough to cover all possible inputs.
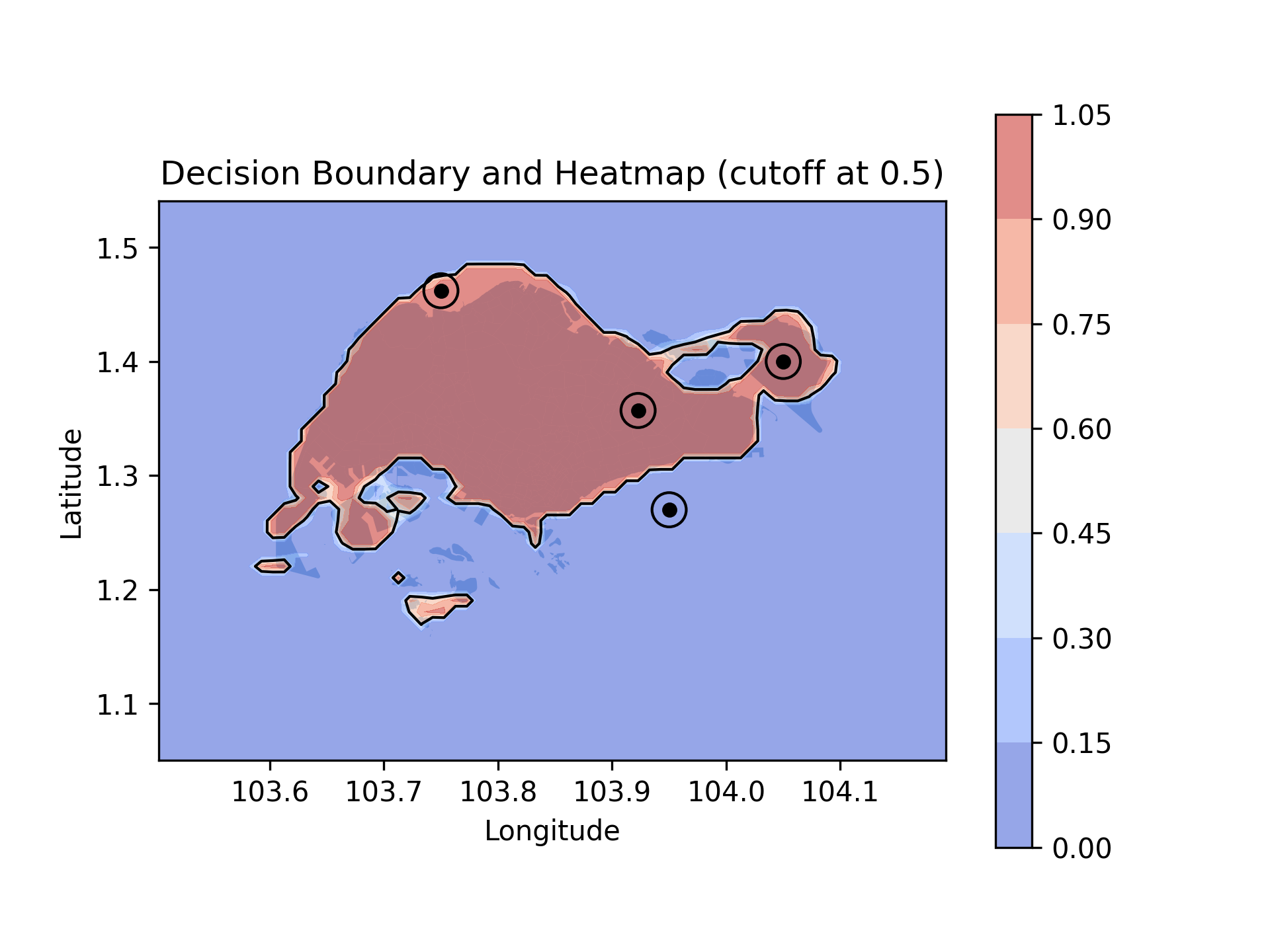 Fig. 4: The trained model fails the input-output specifications. The model fails to cover the top part of the map, where most of the points should be labeled
Fig. 4: The trained model fails the input-output specifications. The model fails to cover the top part of the map, where most of the points should be labeled 0, but are labeled 1 by the model.
Adversarial Examples
In the previous example, we use a simple input-output specification that only checks for the consistency of the model output with the expected output. In practice, the specification can be more complex and involve multiple inputs and outputs. The key idea is to have a formal way to express the expected behavior of the model.
Also, in this example, we can easily visualize the prediction of the model and compare it with the expected output since we are working in a 2D space. Imagine, however, if the input space is high-dimensional (such as images or texts), then the specification can be more complex and harder to visualize. An example of this is the adversarial examples, where a small perturbation in the input space can cause the model to misclassify the input. Adversarial examples are inputs to ML models that are intentionally designed to cause the model to make a mistake. These examples are generated by adding small perturbations to the input data with the intention of amplifying the loss and errors in the model prediction, hence leading to misclassifications. A famous example is this panda image that is classified as a gibbon by the model when a small carefully-optimized noise is added to the image.
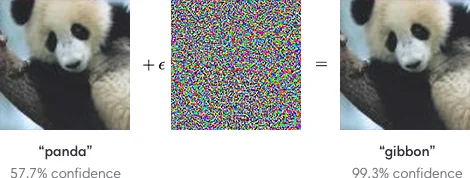 Fig. 5: Adversarial example for image classification. The panda image is classified as a gibbon by the model when an imperceptible adversarial perturbation is added to the image. Source: OpenAI blog.
Fig. 5: Adversarial example for image classification. The panda image is classified as a gibbon by the model when an imperceptible adversarial perturbation is added to the image. Source: OpenAI blog.
In this example, the model fails the input-output specification because the model is not robust to adversarial examples. The process of generating adversarial examples is called adversarial attack.
Adversarial Attacks
There are many adversarial attacks that can fool ML models. These attacks can be used to verify the robustness of ML models to adversarial perturbation, up to a certain radius $\epsilon$. Consider the following example of an adversarial attack on resnet model using foolbox library.
import foolbox as fb
# instantiate the model
model = models.resnet18(pretrained=True).eval()
Preproces an input image and get the model’s prediction.
 Fig. 6: The Merlion image. Source: Wikipedia.
Fig. 6: The Merlion image. Source: Wikipedia.
# get the imagenet class names
classes = fb.utils.imagenet_labels()
# Load and preprocess an image
image = Image.open("./merlion.jpg") # Replace with your image path
image = image.resize((224, 224))
image = np.array(image).astype(np.float32) / 255.0
#transform to tensor
image = torch.from_numpy(image.transpose(2, 0, 1)).unsqueeze(0)
# get the model's prediction
pred = fmodel(image)
prediction = pred.argmax()
The model predicts the image as fountain.
print(f"Prediction: {classes[str(prediction.numpy())]}")
# >>> Prediction: fountain
Now, let’s generate an adversarial example using Fast Gradient Sign Method (FGSM) attack. See the foolbox documentation for more details.
# create the attack
import foolbox as fb
fmodel = fb.PyTorchModel(model, bounds=(0, 1))
attack = fb.attacks.FGSM()
_, advs, success = attack(fmodel, image, prediction, epsilons=[0.01])
# get the model's prediction for the adversarial example
prediction_adv = fmodel(advs).argmax()
print(f"Prediction: {classes[str(prediction_adv.numpy())}")
# >>> Prediction: shower courtain
The model now predicts the adversarial example as shower curtain. This is an example of an adversarial attack that can fool the model to misclassify the input. Let’s see the adversarial example, original image, and the perturbation.
 Fig. 7: The adversarial example of the Merlion image (left, predicted as
Fig. 7: The adversarial example of the Merlion image (left, predicted as shower curtain), the original image (middle, predicted as fountain), and the perturbation (right).
Note again that the perturbation is imperceptible to humans but can cause the model to misclassify the input. Similar to the previous example, the model fails the input-output specifications because the model is not robust (particularly to adversarial examples). See the foolbox documentation for more details on adversarial attacks and defenses.
Acknowledgment
This lecture material is created by the instructor based on the instructor’s knowledge and experience in machine learning and verification and validation. It uses mostly open-source materials and tools, such as Python, PyTorch, and foolbox Python package. The instructor would like to acknowledge the creators and contributors of these tools and materials for making them available to the public.
Copilot has been used to generate the text snippets and terminologies based on the input provided by the instructor. The instructor has reviewed and edited the generated text to ensure accuracy and relevance to the lecture content.
This brief is provided as a pre-reading material for the lecture on Verification and Validation (V&V) for Machine Learning (ML) Models by Mansur M. Arief. For more information, please contact the instructor directly.
Content available online at VandVAIProducts.github.io/ml-verification-example-and-adversarial-attack.